Quand on parle de machine learning supervisé, il est usuel de distinguer deux types de problème en fonction de la nature de l’information que l’on souhaite prédire:
- Si les variables à prédire sont qualitatives, on parle de classification
- Si elles sont quantitatives, on parle de régression
Les modèles de classification estiment une loi de probabilité discrète, tandis que les modèles de régression estiment l’espérance conditionnelle des variables à prédire, c’est à dire leur valeur moyenne sur un grand nombre d’observations.
Mais pourquoi se limiter à apprendre une espérance dans le cas des variables continues ? Pourquoi ne pas apprendre la loi de probabilité comme dans le cas des modèles de classification ?
Une raison officieuse est qu’on ne sait pas trop comment faire ça ! Mais grâce à cet article, vous verrez que c’est en fait très simple dès lors que l’on sait utiliser Keras. Les considérations techniques ne devraient donc pas influer sur le choix de modéliser seulement l’espérance ou bien la distribution d’une variable continue.
Le Notebook Collab
Pour illustrer cet article, j’ai créé un notebook Collab accessible ici. Vous pouvez y accéder librement et créer une copie pour pouvoir exécuter le code et le modifier. Tout tourne en quelques dizaines de secondes, donc pas besoin d’utiliser un GPU ou TPU pour ce projet.
Les Données
Les données qu’on va utiliser sont générées artificiellement. Elles sont constituées d’une variable d’entrée nommé « radius » et deux variables de sortie « x » et « y ».
La variable « radius » est générée selon une loi uniforme continue sur l’intervalle [0, 1]. Quand à « x » et « y » se sont les coordonnées d’un point choisi au hasard sur le cercle de centre (0, 0) et de rayon « radius », auxquelles ont ajoute un bruit gaussien.
Donc, on observe le rayon et on aimerait modéliser la relation entre celui-ci et les coordonnées « x » et « y ». Si on se contentait de modéliser l’espérance de « x » et « y », le résultat serait très décevant: en effet quelque soit le rayon l’espérance est égale à 0, ce qui conduirait à conclure que le rayon n’a aucune incidence sur la valeur de « x » et « y ».
Au lieu de ça, nous allons donc essayer de modéliser la distribution conditionnelle de « x » et « y ».
Sur l’image ci-dessous, on a représenté la distribution empirique et la distribution sachant que le rayon est compris entre 0,5 et 0,6.
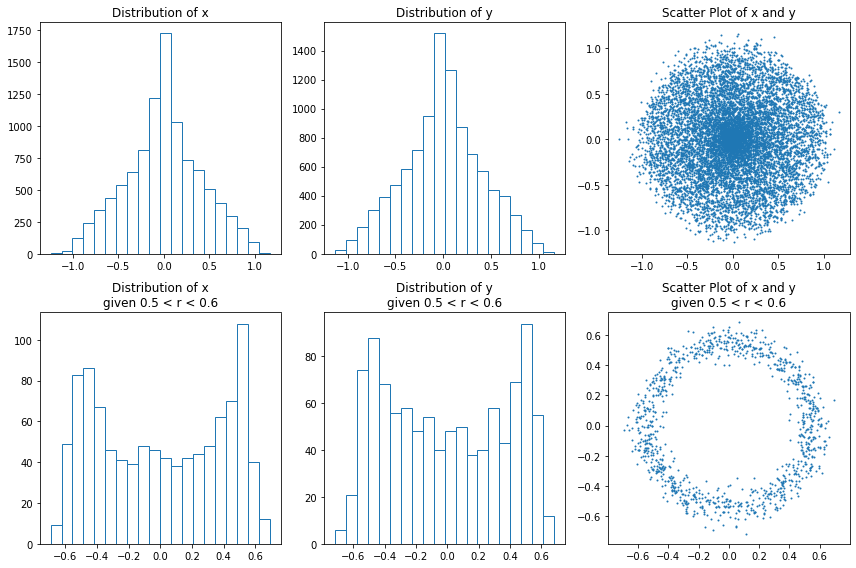
Que l’on regarde la distribution conditionnelle ou non conditionnelle, on constate qu’elle a une forme assez étrange, plutôt éloignée des distributions classiques. Il va donc falloir trouver un moyen de l’approximer.
Le Module tensorflow_probability
En machine learning, il est très courant de modéliser des espérances conditionnelles ou des probabilités discrètes finies. Dans le premier cas, il suffit d’utiliser un réseau de neurones dont la dernière couche est linéaire et dans le second cas, la dernière couche est généralement une couche softmax.
Mais comment faire pour modéliser une distribution continue ? En fait, si vous avez l’habitude d’utiliser « Keras », c’est super simple ! Il suffit d’utiliser le module « tensorflow_probability« .
Ce module, partie intégrante du projet « tensorflow », fournit de nouvelles couches (layers) utilisables dans les modèles créés avec Keras. Au lieu de renvoyer un tenseur, ces couches retournent un objet de classe « Distribution » contenant tous les paramètres de la distribution et disposant de méthodes très pratiques notamment pour générer des données ou pour calculer le maximum de vraisemblance.
Concrètement, on crée un modèle Keras de façon usuelle, sauf que l’avant-dernière couche est une couche linéaire dont le nombre d’unités dépend de la distribution choisie. La dernière couche est quant à elle l’une des couches fournies par le module « tensorflow_probability ».
Voici un exemple de modèle avec une couche cachée retournant une distribution normale.
import tensorflow_probability as tfp from tensorflow import keras n_params = tfp.layers.IndependentNormal.params_size(event_shape=1) model = keras.Sequential([ keras.layers.InputLayer(1), keras.layers.Dense(10, activation="tanh"), keras.layers.Dense(n_params), tfp.layers.IndependentNormal(event_shape=1) ])
C’est franchement simple, non ? Notez qu’on n’a même pas besoin de calculer le nombre de paramètres nécessaires pour la distribution : il y a une méthode pour ça.
Et comment entraine-t-on ce modèle ? On utilise la méthode du maximum de vraisemblance et pour cela on doit définir une fonction de coût personnalisée :
def minus_log_likelyhood(y, distr): return -distr.log_prob(y) model.compile(keras.optimizers.Adam(), minus_log_likelyhood) model.fit(X)
Autrement dit, mis à part la fonction de coût, tout est pareil que pour un modèle Keras classique.
Fonction de Densité Univariée
Revenons sur notre problème initial et dans un premier temps, essayons de modéliser la fonction de distribution de « x » uniquement. Nous avons déjà noté que cette distribution n’est pas classique. Heureusement, nous savons qu’il est possible d’approximer n’importe quelle distribution continue avec un mélange gaussien.
Le module « tensorflow_probability » contient justement une couche appelée « MixtureNormal » qui fait ça !
Dans le notebook, on choisit de prendre dix composantes. Il n’y a pas vraiment de raison précise pour ce choix-là. Si on ne prend pas suffisamment de composantes, l’approximation est imparfaite, si on en prend trop, le temps de calcul augmente et il y a un risque accru de surapprentissage.
# Number of components of the gaussian mixture n_comp = 10 # Number of parameters required by the MixtureNormal layer. n_params = tfp.layers.MixtureNormal.params_size(n_comp, event_shape=1) model = keras.Sequential([ keras.layers.InputLayer(1), # The model has one input variable: the radius keras.layers.Dense(20), keras.layers.LeakyReLU(), keras.layers.Dense(20), keras.layers.LeakyReLU(), keras.layers.Dense(n_params), tfp.layers.MixtureNormal(n_comp, event_shape=1) ])
Dans le notebook Collab, vous pourrez voir que l’entrainement est très rapide et les résultats proches de ce qui est attendu. Mais ce qui nous intéresse vraiment, c’est la distribution jointe de « x » et « y ».
Fonction de Densité Multivariée
La fonction de distribution jointe de x et y est loin d’être une distribution classique : aucune distribution usuelle ne peut générer un cercle. Là encore, pour approximer cette distribution, on peut utiliser un modèle de mélange mais cette fois-ci de gaussiennes multivariées.
Étonnamment, « tensorflow_probability » ne fournit pas de couche « MixtureMultivariateNormal ». Heureusement, il est facile de créer des mélanges de n’importe quelle distribution grâce à la couche « MixtureSameFamily » :
# Number of components
n_comp = 10
# Number of parameters of the multivariate gaussian mixture
n_params = tfp.layers.MixtureSameFamily.params_size(
n_comp,
tfp.layers.MultivariateNormalTriL.params_size(2)
)
model = keras.Sequential([
keras.layers.InputLayer(1),
keras.layers.Dense(20),
keras.layers.LeakyReLU(),
keras.layers.Dense(20),
keras.layers.LeakyReLU(),
keras.layers.Dense(n_params),
tfp.layers.MixtureSameFamily(
n_comp,
tfp.layers.MultivariateNormalTriL(event_size=2) # returns a bivariate normal distribution
)
])
Là encore, l’entrainement est très rapide. Une fois le modèle entrainé, on peut utiliser la méthode « predict » pour générer des points tirés aléatoirement selon la distribution apprise. Dans le graphique ci-dessous, on fait varier le rayon et on génère des points aléatoires. Les bandes rouges indiquent l’intervalle de confiance théorique à 95%.
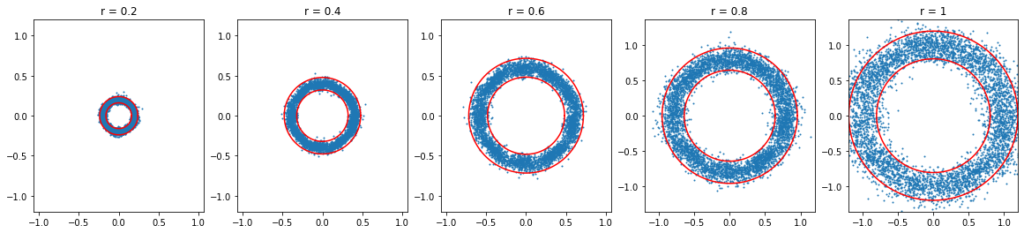
Notre modèle a bel et bien appris à tirer des points aléatoires d’un cercle de rayon prédéfini.
Conclusion
Modéliser la densité de probabilité d’une variable continue est en fait assez aisé avec Keras et tensorflow_probability. Dans ce cas, pourquoi ne pas tout le temps le faire ?
Il ne pas perdre de vue qu’estimer une distribution avec une précision suffisante nécessitera plus de données et de temps de calcul que d’estimer seulement l’espérance. Et le jeu n’en vaut pas toujours la chandelle : dans un grand nombre de problèmes, connaitre l’espérance d’une variable est en fait largement suffisant.
Mais nous verrons dans un prochain article que ce n’est pas toujours le cas et que parfois il est important de pouvoir modéliser une distribution continue.