
Il y a dix ans, j’ai réalisé une rapide étude des mots utilisés dans les professions de foi des candidats à la présidentielle de 2012.
Ce qui était intéressant avec cet article, c’est que les distances sémantiques obtenues étaient révélatrices des stratégies adoptées par les différents candidats. Il montrait par exemple que la profession de foi de Nicolas Sarkozy était sémantiquement proche de celle de Marine Le Pen, ce qui colle avec le fait qu’il lui a été reproché d’essayer de séduire l’électorat d’extrême-droite.
En dix ans, le paysage politique français a beaucoup évolué. Les outils statistiques pour analyser des textes aussi. C’est pourquoi j’ai voulu reprendre ce travail d’il y a dix ans, mais avec les programmes électoraux de 2022 et les méthodes statistiques d’aujourd’hui !
Proximité sémantique des candidats
Avant d’expliquer en détail la démarche statistique, j’aimerais présenter directement les résultats qu’elle permet d’obtenir.
A l’aide d’un modèle word2vec, j’ai calculé la proximité sémantique entre les programmes de chaque paire de candidats. Si deux candidats utilisent des mots similaires dans leur programme, alors ils sont proches. Autrement dit, ils abordent les mêmes thèmes, ce qui ne veut pas forcément dire qu’ils sont d’accord : par exemple « baisse des impôts » et « hausse des impôts » sont sémantiquement proches mais politiquement opposés.
Une fois ces proximités calculées, on peut utiliser un algorithme statistique pour regrouper automatiquement les candidats qui se ressemblent. Les résultats sont représentés sous forme de dendogramme. Ces graphiques se lisent de bas en haut : les candidats sont regroupés de façon itératives en fonction de leur proximité. Plus la jonction se fait bas dans le graphique, plus les candidats sont proches.
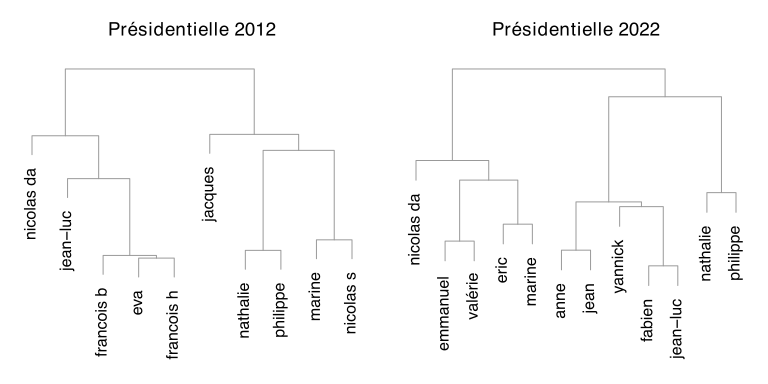
Pour la présidentielle 2012, on retrouve approximativement les mêmes résultats que dans mon précédent article. En résumé, plusieurs candidats inclassables, un groupe de candidats centristes, un groupe de droite et un groupe d’extrême-gauche.
Il est intéressant de voir que pour la présidentielle 2022, l’algorithme a distingué deux groupes : l’un comprenant tous les candidats de droite et l’autre les candidats allant du centre droit (Jean Lassalle) à l’extrême gauche. L’opposition entre la gauche et la droite semble donc toujours existante, au moins dans les discours des candidats. On peut noter que Macron qui se voulait un temps ni de droite ni de gauche ressemble quand même fort à un candidat de droite dans son programme.
Au sein de ces deux grands groupes, on a ensuite de plus petits groupes qui paraissent logiques : au sein de la droite, on a Eric Zemmour et Marine Le Pen d’un côté, Emmanuel Macron et Valérie Pécresse de l’autre. Enfin Nicolas Dupont-Aignan fait bande à part. Dans l’autre groupe c’est un peu plus chaotique. On retrouve un groupe de gauche révolutionnaire, mais il ne contient pas Fabien Roussel. Bien que communiste, il utilise dans sa profession de foi un langage assez modéré comparé à Philippe Poutou ou Nathalie Arthaud et se retrouve de ce fait plus proches du centre que de l’extrême-gauche.
Ici on a étudié séparément les programmes de 2012 et ceux de 2022, mais que se passe-t-il si on les prend tous en compte en même temps ?
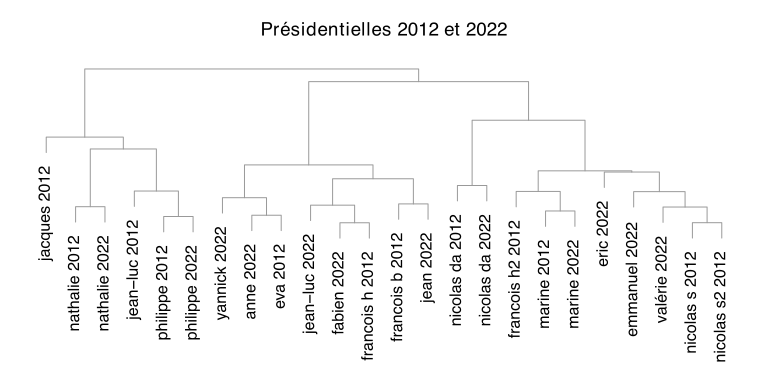
On obtient alors trois groupes : un groupe d’extrême gauche, un groupe allant de gauche à centre-droit et un groupe de droite et d’extrême-droite (et Jacques Cheminade toujours loin de tout le monde). Il est intéressant de voir que les candidats qui se sont présentés aux deux élections ont finalement assez peu changé de discours en dix ans. Une seule exception : Mélenchon qui passe du groupe extrême-gauche en 2012 au groupe « centriste » en 2022.
Qu’est-ce qui distingue les candidats?
La méthode qu’on vient d’utiliser pour regrouper les candidats est très intéressante, mais elle ne nous renseigne pas sur ce qui, d’un point de vue sémantique, rapproche les candidats au sein d’un groupe et ce qui les distingue des candidats des autres groupes.
Pour répondre à cette question, j’ai réalisé une analyse en composante principale. Cette méthode que j’ai déjà présentée dans un autre article permet d’identifier ce qui distingue le plus les candidats. Les deux premières composantes capturent 15% et 13% des différences entre candidats. Les cinq premières composantes capturent ensemble 50% des différences. Dans le tableau ci-dessous on a indiqué les mots les plus positivement et négativement corrélés à chaque composante.
| Composante | % diff | Mots négatifs | Mots positifs |
|---|---|---|---|
| 1 | 15% | prolétariat, capitaliste, krach, faillite, spéculateur, ouvrier, grève, prêteur, banqueroute, dilapider, gréviste, actionnaire, rembourser, employé, dividende, cireur, travailleur, banquier, revendre, spéculer | durable, biodiversité, renouvelable, sensibilisation, écologique, environnemental, intergouvernemental, écologie, énergétique, interministériel, climatique, environnement, bioéthique, prévention, laïcité, soutenable, sensibiliser, quinquennat, préservation, coopération |
| 2 | 13% | commuer, délinquant, parent, évader, casier, enfuir, dyslexique, gracier, pensionnat, internat, incarcérer, naturalisation, alcoolémie, adrianna, marrane, retenter, paternel, brigantin, cachot, purger | capitaliste, capitalisme, prolétariat, salarié, actionnaire, privatisation, nationalisation, travailleur, salariat, prolétaire, socialisme, milliard, salarier, pib, capital, salaire, anticapitaliste, patronat, grève, autogestion |
| 3 | 9% | climatique, déforestation, pollution, écosystème, anthropique, écologique, écologie, biosphère, sécheresse, chorologique, basculeur, biodiversité, abiotique, souffrance, totalitarisme, pesticide, oppresseur, prolétariat, photosynthèse, surexploitation | fiscalité, pme, fiscal, cotisation, délibérant, imposable, intercommunal, socioprofessionnel, suffrage, paritaire, finance, impôt, taxe, escompte, épargne, exonération, collectivité, consignation, bancaire, salarié |
| 4 | 8% | référendum, électoral, législatif, élection, scrutin, suffrage, circonscription, législative, député, abstention, sortant, ratification, recomptage, autonomiste, réélire, colistier, électeur, présidentiel, bicaméral, indépendantiste | salaire, cotisation, chômage, salarié, salarial, allocation, rémunération, salarier, employeur, revenu, invalidité, chômeur, exonération, pension, allocataire, socioprofessionnel, retraité, imposable, emploi, embauche |
| 5 | 7% | organisationnel, gouvernance, incrément, enjeu, managérial, décideur, cohésion, apprenant, rationalité, cohérence, pluridisciplinarité, épistémologique, interpersonnel, neume, binôme, innovation, structuration, sociétal, scientificité, informationnel | euro, salaire, amende, indemnité, taxe, milliard, dollar, centime, million, forfaitaire, loyer, tarif, imposable, nuitée, cotisation, surtaxe, $, rançon, perpétuité, dirham |
La première composante semble opposer grosso-modo économie et écologie tandis que la seconde oppose très clairement les thèmes d’extrême-droite (sécurité, identité) et d’extrême-gauche (nationalisation, socialisme). Les autres composantes sont plus difficiles à interpréter.
Encore une fois, l’opposition gauche/droite semble toujours présente dans les programmes. Mais ce qui distingue le plus les programmes, c’est finalement la place accordée à l’écologie.
Dans le graphique ci-dessous on a représenté la position des candidats sur les deux premières composantes.
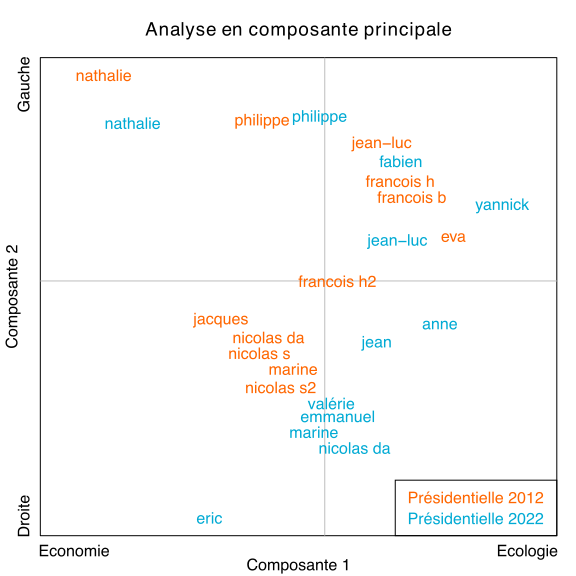
En ne prenant en compte que ces deux dimensions, on retrouve à peu près les groupes identifiés dans la partie précédente. Mais ce graphique apporte de nouvelles informations. On peut par exemple remarquer qu’en 2022, les candidats donnent davantage d’importance à l’écologie. Il ne s’agit pas seulement d’un changement d’offre politique : les candidats déjà présents en 2012 se sont tous déplacés dans la direction de l’écologie en 2022.
On peut également remarquer la proximité entre Marine Le Pen et les candidats de droite. On peut imaginer que c’est là le reflet d’une part de la stratégie de dédiabolisation menée par Le Pen et d’autre part de la tentative des candidats de droite de séduire l’électorat d’extrême-droite.
Bref, il y aurait sans doute beaucoup à dire encore, mais je vous laisse libre de tirer vos propres conclusions.
Décrire un texte avec word2vec
Les méthodes statistiques employées dans les sections précédentes nécessitent toutes les deux comme entrée un tableau numérique contenant une ligne par candidat. Or, nos données, ce sont des textes ! Comment transforme-t-on un texte en une série de nombres ?
Il y a dix, ce qui se faisait généralement c’était de créer un immense tableau avec une ligne par document et une colonne par mot, chaque case indiquant l’importance du mot dans le document. Le problème c’est que cela donnait des tableaux immenses (potentiellement des dizaines de milliers de colonnes) et souvent difficiles à exploiter car remplis de cases vides. En particulier, les mots qui n’apparaissaient que dans un seul document étaient inutilisables quand bien même ils pouvaient être très révélateurs.
Les modèles de type word2vec sont apparus en 2013 pour résoudre ces problèmes. Il s’agit de modèles de réseaux de neurones qui apprennent pour chaque mot une représentation numérique (appelée en anglais « word embedding »).
Autrement dit, ces modèles permettent de convertir les mots en vecteur de nombres. Il est difficile de savoir ce que représente exactement chacun de ces nombres, mais deux mots qui sont très proches sémantiquement (c’est-à-dire qu’ils apparaissent souvent dans le même contexte) auront une représentation proche. Ainsi au lieu d’avoir des dizaines de milliers de colonnes remplies de 0, on se retrouve avec quelques centaines de colonnes. De plus les mots uniques peuvent quand même être comparés aux autres mots employés dans les différents textes.
Pour représenter numériquement un texte tout entier (et pas seulement un mot), on commence par transformer tous les mots qui le constituent en vecteur de nombre avec un modèle word2vec. Puis if suffit de faire la moyenne de chaque colonne ! Ça peut paraître un peu étrange de faire une moyenne des mots, mais empiriquement, ça fonctionne plutôt bien, comme vous aurez pu le constater dans les sections précédentes.
Une fois qu’on a transformé chaque texte en un vecteur, on peut utiliser les méthodes statistiques usuelles. Mais ce n’est pas tout ! On peut également utiliser le modèle word2vec pour chercher les mots qui sont les plus proches d’un vecteur. Ca peut être une façon intéressante de résumer le contenu d’un texte ou d’un groupe de textes. Par exemple, dans le tableau ci-dessous on a indiqué les mots qui caractérisent chaque programme.
| Candidat | Mots caractéristiques |
|---|---|
| Anne | solidarité, responsabilisation, démocratie, prolétariat, égalité, réinsertion, sensibiliser, équité, prévoyance, entraide, social, défavoriser, égalitaire, sensibilisation, autonomisation, décent, socioprofessionnel, salaire, liberté, autogestionnaire |
| Éric | impôt, pension, amende, subvenir, citoyenneté, indemnité, cotiser, payer, fiscal, précaire, contribuable, gabelle, salaire, imposable, revenu, immigré, délinquant, exonérer, capitation, taxe |
| Fabien | salaire, chômage, salarial, allocation, cotisation, socioprofessionnel, votation, indemnité, salarié, discrimination, précarité, chômeur, dépense, rémunération, impôt, solidarité, revenu, péréquation, pib, invalidité |
| Jean | privatisation, intergouvernemental, gouvernance, subsidiarité, décentralisation, défavoriser, compétitivité, budgétaire, responsabilisation, superpuissance, péréquation, autosuffisance, logement, votation, épargne, financement, parité, mixité, institution, volontariat |
| Jean-Luc | cotisation, salaire, solidarité, impôt, subvention, allocation, péréquation, rémunération, libéraliser, salarial, indemnité, allocataire, équitable, gratuité, kipling, solidaire, tarif, intéressement, précarité, revenu |
| Emmanuel | cotisation, assuré, invalidité, cotisant, allocation, rémunération, allocataire, cotiser, rémunérer, salarial, responsabilisation, salaire, dépense, subvenir, revenu, pension, précarité, péréquation, garderie, déductible |
| Marine | précarité, chômage, paupérisation, impôt, inflation, votation, pauvreté, insécurité, protectionniste, allocation, salaire, socioprofessionnel, externalité, salarial, contribuable, cotisation, monopole, immigration, récession, privatisation |
| Nathalie | salaire, salarial, prolétariat, travailleur, salarié, capitaliste, chômeur, salarier, chômage, cotisation, salariat, employeur, allocation, rémunérer, rémunération, socioprofessionnel, précarité, pme, ouvrier, intéressement |
| Nicolas | votation, référendum, garderie, conscription, dépénaliser, indigénat, multipartisme, reconduite, quinquennat, salaire, parental, pénal, fiscal, volontariat, défavoriser, allocation, abrogation, pénitentiaire, cotisation, dépénalisation |
| Philippe | prolétariat, capitaliste, démocratie, salarial, salariat, capitalisme, autogestion, égalitaire, solidarité, protectionniste, discrimination, redistribution, salaire, protectionnisme, nationalisation, multipartisme, démocratisation, socioprofessionnel, pacifisme, responsabilisation |
| Valérie | cotisation, salaire, chômage, allocation, chômeur, revenu, salarial, impôt, gratuité, rmi, prévoyance, allocataire, invalidité, précarité, assuré, garderie, votation, défiscalisation, solidarité, rémunération |
| Yannick | soutenable, renouvelable, durable, environnemental, climatique, déforestation, biodiversité, énergétique, précarité, sensibiliser, écologique, sensibilisation, défavoriser, externalité, pauvreté, désertification, logement, pollution, solidarité, inégalité |
De manière similaire, on peut faire la différence entre les vecteurs de deux documents, puis convertir en mot cette différence pour comprendre ce qui distingue les deux documents.
Par exemple, on a vu que Mélenchon est l’un des seuls candidats dont le discours a sensiblement évolué entre 2012 et 2022. Avec la méthode qu’on vient de décrire, on comprend immédiatement qu’en 2022, il parle moins de changement de la constitution et du système financier et introduit de nouveaux thèmes : la scolarité, la santé et le handicap.
| thèmes perdus entre 2012 et 2022 | Thèmes gagnés entre 2012 et 2022 |
|---|---|
| abrogation, abroger, boursier, ratification, référendum, banque, amendement, bancaire, promulgation, krach, promulguer, inconstitutionnel, nationalisation, veto, législation, constitutionnalité, loi, constitutionnel, ségrégation, abolition | cotisation, pédagogique, crans, interdisciplinarité, soignant, tutorat, pédagogie, pédopsychiatrie, handicap, impôt, doctorant, coaching, ludique, macrocosme, liez, interdisciplinaire, ludothèque, reverser, téléthon, euro |
Faites-le vous-même avec R
Vous pouvez récupérer les données utilisées ci-dessous. Pour la présidentielle 2022, les professions de foi ont été récupérées sur ce site au format PDF. J’ai ensuite copié le texte et collé dans des fichiers texte. Pour la présidentielle 2012, j’avais scanné moi-même les programmes puis utilisé un logiciel d’OCR pour les convertir en texte. J’ai corrigé les erreurs manuellement, mais il en reste probablement plein.
Pour le modèle word2vec, j’ai récupéré sur cette page un modèle préentrainé sur les articles francophones de Wikipedia. Merci à Jean-Philippe Fauconnier d’avoir créé et mis à disposition ces modèles.
Avec le bout de code suivant, vous pouvez récupérer les données et le modèle en toute simplicité :
# Téléchargement du modèle word2vec préentrainé. Cela peut prendre quelques minutes.
options(timeout=600)
download.file(
"https://embeddings.net/embeddings/frWiki_no_phrase_no_postag_700_cbow_cut100.bin",
destfile = "frWiki_no_phrase_no_postag_700_cbow_cut100.bin"
)
# Récupération des données
download.file(
"https://francoisguillem.fr/wp-content/uploads/2022/04/programmes_presidentielle_2022.zip",
destfile = "programmes.zip",
)
unzip("programmes.zip", exdir = "programmes")
Sans surprise, j’ai utilisé pour cette étude la biliothèque « word2vec », ainsi que quelques autres bibliothèques pour préparer les données ou analyser les résultats :
# Chargement des bibliothèques library(dplyr) library(word2vec) library(tm) library(koRpus) library(koRpus.lang.fr) library(lsa) # Cosine similarity library(FactoMineR) # analyse factorielle
La biliothèque « word2vec » est très simple à utiliser. On charge un modèle avec « read.word2vec() » puis on utilise la fonction « predict() » soit pour récupérer les mots les plus proches d’un mot soit pour obtenir la représentation numérique d’un mot (ici un vecteur de longeur 700).
# Chargement du modèle word2vec préentrainé.
w2v_model <- read.word2vec("frWiki_no_phrase_no_postag_700_cbow_cut100.bin")
predict(w2v_model, c("chat", "chien"), top_n = 3)
# $chat
# term1 term2 similarity rank
# 1 chat chat 0.5888417 1
# 2 chat félin 0.4479723 2
# 3 chat chaton 0.4294741 3
#
# $chien
# term1 term2 similarity rank
# 1 chien chien 0.6132408 1
# 2 chien canin 0.4921678 2
# 3 chien lévrier 0.4556154 3
predict(w2v_model, c("chat", "chien"), type = "embedding")
# [,1] [,2] [,3] [,4] [,5] ...
# chat -0.2125163 -0.67273158 0.8406934 0.6751714 -0.5447465 ...
# chien 0.0914526 0.08574963 0.4448672 -0.1223802 0.7644746 ...
On peut également passer à la fonction « predict() » un vecteur ou une matrice et elle renvoie les mots les plus proches :
predict(w2v_model, rnorm(700), top_n = 3) # term similarity rank # 1 avitaillement 0.3700943 1 # 2 rez 0.3570630 2 # 3 magnitude 0.3439153 3
Vectorisation des documents
Avant de transformer chaque programme en un vecteur numérique, On commence par lemmatiser tous les mots, c’est à dire les mettre sous leur forme canonique (en minuscule, à l’infinitif pour les verbes, au singulier masculin pour les pour les adjectifs). Pour cela, on utilise le logiciel Treetagger, qui doit être installé séparément. N’oubliez pas d’installer le fichier de paramètres pour le français.
Une fois le texte converti en lemmes, on retire les « stopwords », ie. les mots ultra fréquents qui n’apportent que très peu d’information (par exemple, le, la, et, que…). On ne conserve que les noms, verbes et adjectifs. Enfin on convertit tous les mots en vecteurs numériques, puis on fait la moyenne pour chaque document.
Toutes ces opérations sont réalisées par le morceau de code ci-dessous. Il renvoie une matrice avec une ligne par programme et 700 colonnes (c’est le nombre de dimensions du modèle word2vec utilisé).
# Vectorizer les programmes présidentiels
files <- list.files("programmes", pattern = ".txt$")
candidates <- gsub(".txt", "", files)
vectorized_docs <- sapply(files, function(f) {
tagged.text <- treetag(
file.path("data", f),
treetagger="manual",
lang="fr",
stopwords = stopwords("fr"),
TT.options=list(
path="~/treetager/",
preset="fr"
)
)
words <- tagged.text@tokens %>%
filter(grepl("VER|NOM|ADJ", tag), !stop, lemma == tolower(lemma)) %>%
pull(lemma)
vectorized_words <- predict(w2v_model, newdata = words, type = "embedding")
colMeans(vectorized_words, na.rm = TRUE)
})
vectorized_docs <- t(vectorized_docs)
row.names(vectorized_docs) <- candidates
Il est possible de trouver les mots « caractéristiques » d’un programme avec la ligne de code suivante :
predict(w2v_model, vectorized_docs["emmanuel 2022",], top_n = 20)
Similairement, pour voir ce qui distingue deux programmes (par exemple ce qui a changé entre 2012 et 2022 pour Mélenchon), on fait la différence entre les deux lignes correspondantes puis on utilise le modèle word2vec pour caractériser cette différence :
predict(w2v_model, vectorized_docs["jean-luc 2012",] - vectorized_docs["jean-luc 2022",]) predict(w2v_model, vectorized_docs["jean-luc 2022",] - vectorized_docs["jean-luc 2012",])
Analyse des programmes
Maintenant qu’on dispose d’un tableau avec seulement des valeurs numérique et avec une ligne par document, on peut utiliser les méthodes d’analyse usuelles. Ici, j’ai utilisé la fonction « hclust() » pour le regroupement hiérarchique et « PCA() » pour l’analyse factorielle.
# Regroupement hiérarchique ascendant
dist_matrix <- 1 - cosine(t(vectorized_docs))
clusters <- hclust(as.dist(dist_matrix), method = "ward.D2")
plot(clusters, yaxt="n", main = "Présidentielles 2012 et 2022")
# Analyse en composante principale
pca <- PCA(vectorized_docs, scale.unit = TRUE)
# Identifier les mots corrélés à chaque composante
pca_explanation <- lapply(1:5, function(i) {
data.frame(
component = i,
negative = paste(predict(w2v_model, -pca$var$coord[,i], top_n = 20)$term, collapse = ", "),
positive = paste(predict(w2v_model, pca$var$coord[,i], top_n = 20)$term, collapse = ", "),
stringsAsFactors = FALSE
)
})
Une réponse à “Analyse des Programmes de la Présidentielle 2022 avec Word2vec”
Super intéressant ! Merci pour le partage (et le boulot !).