Lorsque je ne fais pas des statistiques, je lis des bandes dessinées et en particulier des Picsou Magazine ! Cela fait plus de dix-huit que j’achète et que je collectionne ce merveilleux magazine.
Comme tout bon collectionneur, je tiens à jour un fichier contenant la liste de tous les numéros que je possède et de leur état. Je me demandais s’il était possible de tirer quelque chose de ces données. Eh bien c’est le cas !
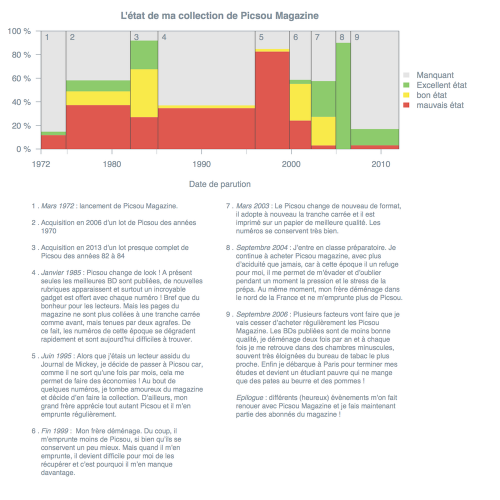
Si l’on regarde la quantité et l’état de mes Picsou en fonction de leur date de publication on peut observer des points de rupture : sur certaines périodes, j’ai presque tous les numéros, alors que sur d’autres, j’en ai très peu. A l’aide d’un algorithme statistique, on identifie précisément tous ces points de rupture.
Ce qui est frappant, c’est que chacun de ces seuils correspond soit à un changement dans le magazine, soit à un évènement marquant dans ma vie. Regardez par vous-même :
Faites le vous même avec R
Pour identifier les seuils, on commence par créer pour tous les Picsou une variable « Etat » qui vaut « manquant » si je n’ai pas le numéro et sinon « mauvais », « bon » etc. selon son état. Ensuite on utilise un arbre de régression pour essayer de prédire l’état d’un Picsou en fonction de sa date de publication.
Mon approche n’est pas très conventionnelle (en regardant le code, vous verrez que je bidouille pas mal), mais ça marche franchement bien !
library(data.table)
# Récupération des données
picsou <- read.csv2(url("http://francoisguillem.fr/data/picsou.csv"))
picsou <- data.table(picsou, key = "Numero")
# Cette ligne permet de faire apparaitre les Picsou manquants dans le tableau
data <- picsou[J(1:max(picsou$Numero))]
data$Mois <- (864 + data$Numero) %% 12 + 1
data$Annee <- 1900 + (864 + data$Numero) %/% 12
data[is.na(Etat), Etat := "Manquant"]
# Arbre de régression
reg <- tree(Etat ~ Numero, data = data)
plot(reg)
text(reg)
# récupération des seuils. tree n'a pas été conçu pour ça. Du coup on
# bidouille pas mal
seuils <- reg$frame$splits[,1]
seuils <- seuils[seuils != ""]
seuils <- gsub("<", "", seuils)
seuils <- as.numeric(seuils)
seuils <- sort(seuils)
# Découpage des données en périodes
data$Periode <- cut(data$Numero, breaks=c(0, seuils, Inf),
labels=1:(length(seuils) + 1))
# Résumé de chaque période. On regroupe les classes afin d'avoir une vision
# plus synthétique
data$Classe <- data$Etat
levels(data$Classe) <- c("mauvais", "mauvais", "excellent", "excellent",
"bon", "Manquant")
periodes <- data[, as.list(prop.table(table(Classe))), keyby = Periode]
# Graphique
seuilsAn <- c(1900 + (864 + c(1, seuils)) / 12, 2012)
gr <- rgb(124, 144, 156 ,max = 255)
cols <- c(gray(0.9), hsv(0.33, 0.5, 0.8), hsv(0.15, 0.8, 1), hsv(0.01, 0.7, 1))
pdf("output/picsou.pdf", 10, 10)
par(col.axis = gr, col.lab = gr, fg = gr)
oldpar <- par(xaxs='i',yaxs='i', las = 1, mar = c(35,4,3,10) + 0.1)
plot(c(seuilsAn[1], 2012), c(0, 100), type = "n",
xaxt = "n", yaxt = "n", xlab = "Date de parution", ylab = "")
axis(1, at = c(seuilsAn[1], 1980, 1990, 2000, 2010),
label = c(1972, 1980, 1990, 2000, 2010))
axis(1, at = c(1975, 1985, 1995, 2005), lwd.ticks=0.5, label = rep("", 4))
axis(2, at = 0:5 * 20, label = paste(0:5 * 20, "%"))
rect(seuilsAn[1], 0, 2012, 100, border=gr, col = cols[1])
for (i in 1:nrow(periodes)) {
rect(seuilsAn[i], 0,
seuilsAn[i+1], periodes[i, mauvais] * 100,
border=NA, col = cols[4])
rect(seuilsAn[i], periodes[i, mauvais] * 100,
seuilsAn[i+1], periodes[i, mauvais + bon] * 100,
border=NA, col = cols[3])
rect(seuilsAn[i], periodes[i, mauvais + bon] * 100,
seuilsAn[i+1], periodes[i, mauvais + bon + excellent] * 100,
border=NA, col = cols[2])
}
segments(seuilsAn, 0, seuilsAn, 100, col = gray(0.3))
text(seuilsAn + 0.7, 95, labels=1:length(seuilsAn))
legend("right", xpd = TRUE, inset = c(-0.2, 0), bty = "n",
legend = c("Manquant", "Excellent état", "bon état", "mauvais état"),
fill = cols, border = NA)
title("L'état de ma collection de Picsou Magazine", col.main = gr)
par(oldpar)
dev.off()